Going Beyond Hill Climbing: Building a Continuous Evaluation System for Real-World Coding Agent Performance
When Benchmark Scores No Longer Equal Product Experience
Over the past two years, large model evaluation standards have undergone several key evolutions. With each evolution, the industry has tried to answer an increasingly difficult question: Are models actually becoming more useful?
SWE-bench Verified was an important starting point. It was the first to advance evaluation from "writing a few pieces of code" to "solving a complete issue in a real GitHub repository." Models need to understand project structure, locate problems, generate patches, and pass test verification. Around the same time, LMSYS launched Chatbot Arena. It chose a different path: no predefined tasks, no automatic scoring, but letting real users make judgments in blind tests. Through pairwise comparison and Elo scoring, user experience was systematically quantified into the evaluation system for the first time. Code Arena went even further, focusing on whether code is efficient, whether interaction is smooth, and whether the model truly understands the user's design intent. These benchmarks have pushed the entire industry forward. But in 2025, we're seeing an increasingly obvious gap: high scores on public leaderboards are gradually losing their connection with real product experience. Models continue to break pass rate records on SWE-bench and steadily rise in Elo on Arena, but when they're placed in real IDEs, real teams, and real ambiguous requirements, performance isn't always stable, and user retention doesn't necessarily improve in sync.
The Common Bottleneck of Competitive Evaluation
Whether it's the classic SWE-bench verified or Code Arena, they are essentially competitive evaluations—designing a track and having models compete for superiority. This logic is very effective in academic research and public comparisons, but when it's directly used for product iteration decisions, problems emerge.
First is the solidification of task distribution. User question distribution tends to stabilize, models begin to "learn the exam," and differentiation decreases.
Second is the black box effect of result orientation. A score or ranking can hardly tell the R&D team what specifically needs optimization.
Most critically is snapshot-style evaluation. All leaderboard evaluations measure model performance at a single moment. They cannot track how capabilities change with version evolution, cannot answer: Have the bugs fixed in the previous version introduced new regressions? In the long term, are model capabilities fluctuating or steadily converging?
There's a very accurate quote in the Code Arena paper: "The question is no longer whether the model can write code, but how it builds real applications end-to-end."
But if we push further, the question might need to go one layer deeper: Can the model stably, continuously, and in your product scenario build applications—and make user experience better and better?
This isn't a question that one evaluation can answer. This requires a completely different evaluation mindset.
We Choose to Start from Real Usage
It's with this question in mind that we've built a completely user experience-oriented rolling evaluation system around model and agent performance
This system is based on crowdtesting, combined with engineering evaluation methods, assisting multiple top-tier AI companies to continuously deliver trustworthy, traceable, and reusable evaluation data, making every product iteration traceable. What we care about has always been: Are models and Agents truly getting better in real usage scenarios? Are they truly improving user experience?
This means several things.
First, evaluation is not a one-time event, but a continuous process. We conduct long-term tracking of the same model across versions. With each model iteration, our expert engineers regenerate tasks using that day's fresh development requirements within the same expert pool and the same scoring standards, to measure whether it has actually improved or regressed. This makes regression alerts and capability trend analysis possible.
Second, evaluation granularity must be sufficient. We don't just look at final results, but conduct structured scoring of each interaction process: delivery completeness, tool invocation rationality, error identification and repair capability, contextual understanding depth, and user experience fluidity. Each round of scoring directly produces high-quality supervision data that can be used for SFT, RL, or even prompt optimization. Behind the scores are traceable judgment reasons and reusable training data.
Third, evaluation scenarios must come from real usage scenarios. Evaluation experts work in real IDE environments, constructing tasks based on their own technical stacks and development needs. This ensures that data distribution always stays close to scenarios users will actually encounter, including long-tail requirements not covered by public benchmarks.
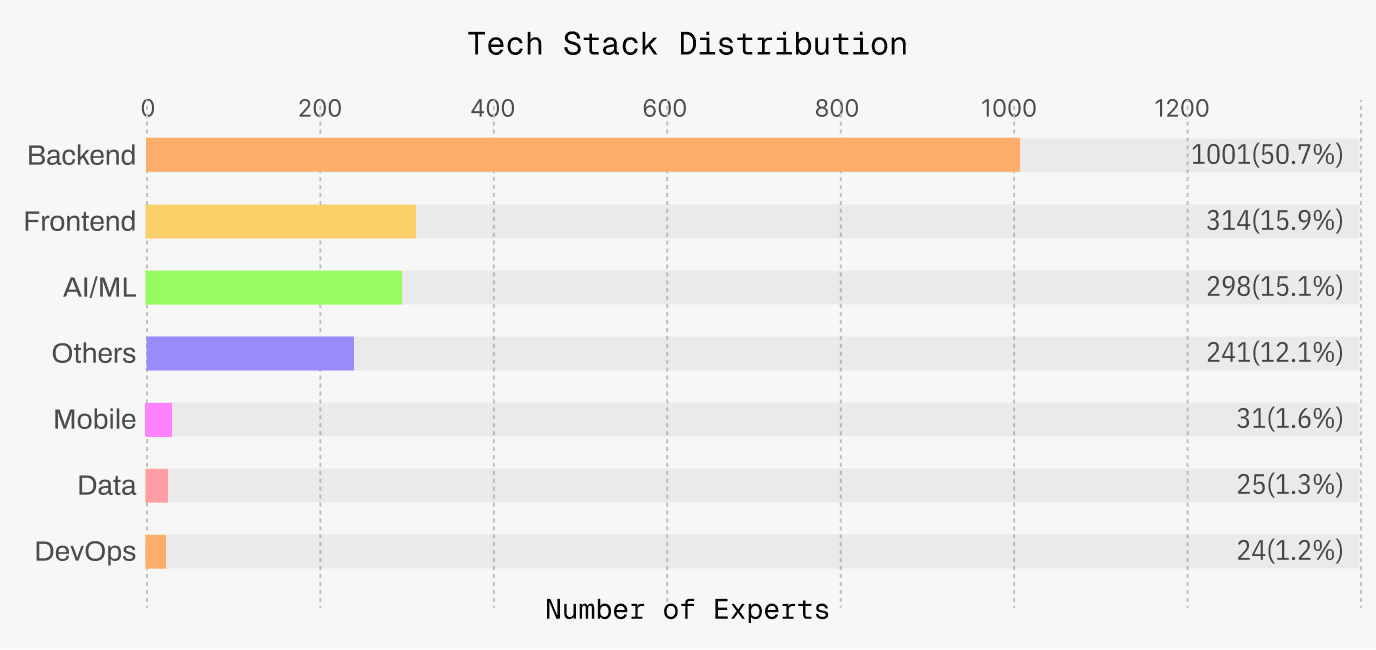
Ignite Experts comes with diversed developing background to cover real world scenario.
Ignite's Approach to Evaluating Coding Models and Agents
The key to evaluation isn't just "what to evaluate," but more importantly "how to generate data." We have no fixed question bank. Experts propose real requirements online based on their own technical stacks, business scenarios, and resource constraints. Task distribution is always changing, and models can never "memorize answers." This means what we test is naturally close to the real scenarios users will encounter tomorrow. In terms of evaluation content, we provide different services for different needs:
1. Single model capability stability and trend observation: Long-term monitoring of the same model's performance on similar tasks, used for regression alerts and long-term optimization
2. Dual model GSB (Good/Same/Bad) comparative evaluation: Give two models the same prompt, fine-grained comparison of Good/Same/Bad, fine-grained evaluation of developer experience and acquisition of optimization rubrics
3. Three-model ranking evaluation: Provides high-confidence relative ranking for version releases These three types of evaluation can be flexibly combined, both providing quick conclusions and running long-term for trend analysis.
More importantly, we're not satisfied with just giving an overall score. We break down the entire interaction process into structured scorable dimensions: whether tool invocation is reasonable, whether contextual understanding is adequate, ability to identify and fix one's own errors, completeness of final delivery. Through structured scoring records, we obtain a complete interaction trace and clear judgment reasoning. This data not only guides product decisions, but the generated traces/trajectories and scoring rubrics can be directly used for subsequent model training.
To make all this scalable, we've transformed crowdtesting into an engineered data production line: standardized processes, multiple quality checks, cross-validation, strict expert admission and permission management, ensuring quality doesn't depend on individual expert preferences.
Supporting this production line is a mature "expert crowdtesting" system. We've established clear expert stratification and task grading mechanisms, ensuring evaluators possess real development capabilities matching task difficulty. Converting non-standard crowdtesting into standard data production is the core capability we've repeatedly refined over the past year.
Currently, the expert network covers mainstream technology stacks, and includes engineers with different years of experience and big tech backgrounds. Some experts are in full-time available status and can quickly respond to high-intensity project requirements.
Particularly important for top technology companies, we've made systematic designs at the security and compliance level—graded isolation of tasks and data, expert permission management, data access control. These mechanisms ensure evaluation data security meets the strictest enterprise requirements.
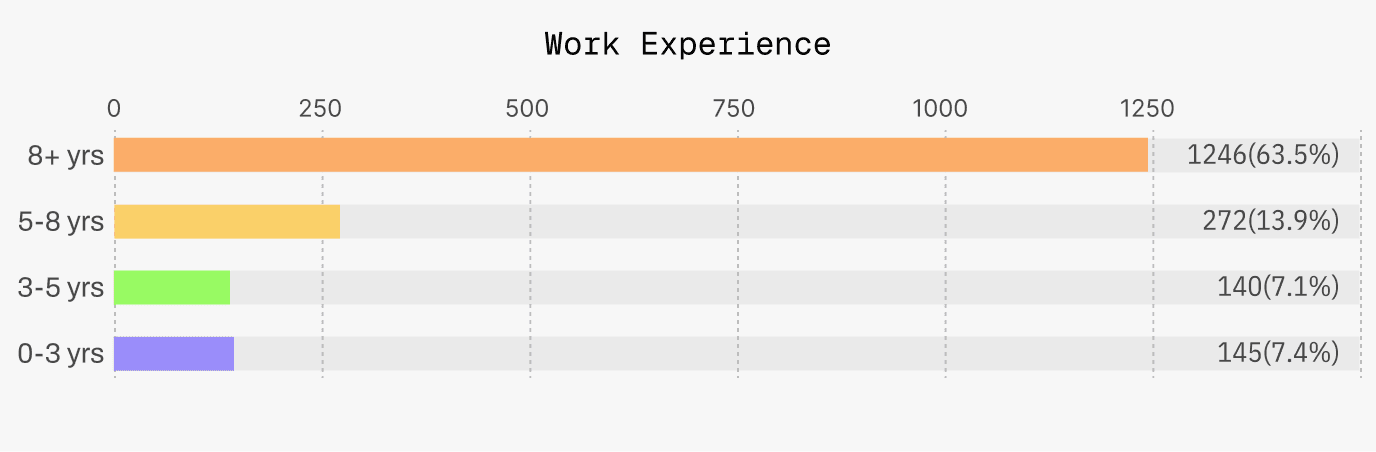
Ignite Experts are mostly seasoned coders with 8+yrs of experience.
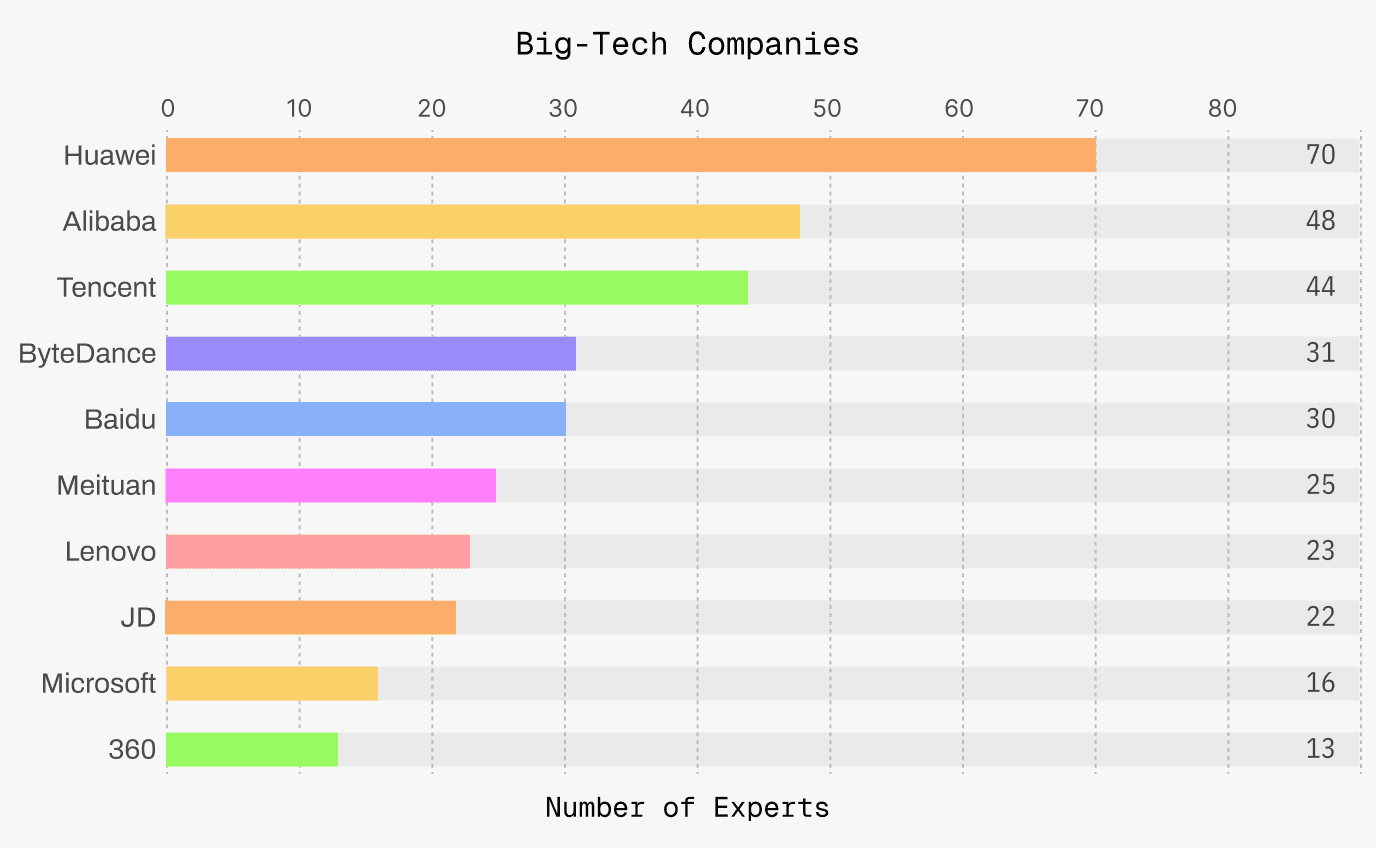
Ignite Experts have successful careers at large tech companies.
The Value of Long-Term Crowdtesting
Over the past period, we've completed continuous quarterly rolling deliveries for multiple frontier AI labs around Agent and AI IDE scenarios, with ongoing cooperation to this day. Our evaluation systems and throughput have been fully validated in real business environments.
As of the initial question: Why do high benchmark scores often fail to directly translate into product experience improvements? Perhaps the reason isn't complicated. "Strong capability" does not always lead to "good user experience " : it has to be tuned on real scenarios, version evolution, and continuous iteration through time. One-time snapshot evaluation could only answer whether a model "can do it"; but only continuous, rolling evaluation can truly answer whether a model is "easy to use," "stable," and "getting better."
We believe that as AI Agents move toward real product implementation, evaluation itself needs to complete a paradigm upgrade—from being ranking-centered to being centered on long-term user satisfaction; from focusing on leaderboard rankings to providing actionable signals; from one-time result delivery to being a indespensible section of the product iteration cycle.